
1.0 AI’s Role in Agile Continuous Learning
There are seismic shifts in the learning environment globally. The conventional 4-year undergraduate and 2-year graduate structured in-person learning model appears to be increasingly losing relevance. The continuous exponential growth of knowledge influx on the internet, connectedness through online communities and social media and the low cost of infrastructure have come together as a perfect storm to upend the conventional higher ed model that has served us so well over the past many decades. The covid pandemic has acted as a catalyst in this acceleration.
At the same time, the accelerated adoption of AI and Automation is impacting the demand side for education. Many tasks in various jobs and potentially entire jobs are being automated increasing the rate of skill obsolescence. Learners will be required in the future to learn new skills rapidly and to adapt rapidly to changes in the work environment. Employers will need work ready employees and increasingly prefer skills necessary for specific jobs and roles.
All of the above suggest the critical need for agile continuous learning paradigms. AI holds enormous potential to help us achieve such a paradigm and enable higher ed institutions adapt to this new world of continuous agile learning. In the same vein, AI also can enable us to achieve such a learning paradigm equitably at scale.
In this paper, we present Gyan for Higher Education, an agile continuous learning platform.
2.0 AI Components for Agile Continuous Learning
An effective framework for Agile Continuous Learning must include the following core elements:
1. The ability for learners to self-learn from a continuously refreshed knowledge portal, with or without assessment and micro-credentials
2. The ability to rapidly assemble, organize and synthesize new learning content from within and outside an institution’s content library and keep it constantly updated.
3. Automated, explainable assessment of open responses scored against a rubric.
4. Skills based, career and demand driven personalization of the learning journey.
Fig. 1 presents a set of components that together address the above elements.
Fig. 1
Gyan Technology for Continuous Learning

3.0 Continuous Knowledge Portal & Lifelong Learning
An essential component for the continuous learning is the ability to gather knowledge continuously. The fundamental challenges behind setting up a mechanism for Continuous Knowledge acquisition is content discovery, organization and synthesis. Search engines have provided immense value in providing access to information where we had no access before. But they only provide access and that is the starting point for content discovery. And even in providing access, current search engines, whether on the internet or private document repositories, generate substantial false positives and false negatives [Srinivasan & Jatav, 2022].
The magnitude of irrelevance in search engine results is only the first issue. This step is the ‘access’ step of the research task. Today’s technologies provide no assistance with the remaining steps. Once a knowledge worker identifies and obtains relevant documents, the next step is to organize them for effective manual processing. This can be in the form of organizing them into sub-topics. Then the human has to read each document, understand and synthesize the knowledge in each document and develop an aggregate understanding across all documents. Further, knowledge acquisition is not one time and therefore, the research output will need to be continuously updated with fresh knowledge on the topic. Current search technologies are incapable of providing automated assistance for the full research or knowledge acquisition process from unstructured content.
Gyan can automatically create continuous knowledge collections on any topic in its Continuous Knowledge Portal. It can find relevant content on any topic from one or more sources, organize them either under pre-specified topics or derive topics from the collection of relevant content, understand each of the relevant content items, summarize each item and synthesize the knowledge across all relevant items. It can also keep the Gyan continuously updated. Fig. 2 illustrates an excerpt from a Gyan on Electric Vehicles.
Fig. 2
Example Gyan – Automated Discovery, Curation and Synthesis of Learning Module on Electric Vehicles

The Portal can facilitate self-learning. Fig. 3 shows a collection of Gyans on a variety of topics. An institution can provide the Portal to its lifelong learners by coupling the Portal with assessments and credentials. Faculty or course designers can manage the content which learners have access to. Faculty can annotate Gyan content as they see fit to impart their knowledge and pedagogy.
The Portal can also be the instructional designer’s continuous automated research assistant to rapidly build and maintain micro learning units. This is explained in greater detail later in the paper.
Fig. 3
Gyan Knowledge Portal: Real-time Learning Content Library

4.0 Rapid Learning Unit Assembly (Course Authoring)
The GyanAI Learning Content Authoring/Assembly Component (Fig. 4) enables any institution to rapidly assemble learning content on a new topic or topics related to a specific skill. Gyan uses its natural language understanding engine to disaggregate the content down to a concept level. It can ingest existing learning content in all formats. It can also augment the content with new content from external repositories like other private learning content collections or the public internet.
Fig. 4
Gyan Learning Content Creation Machine
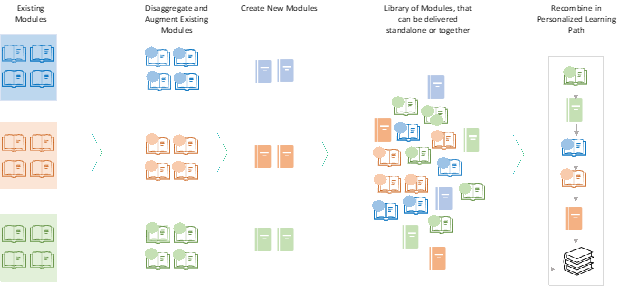
Gyan compiled micro learning units can then be presented to Learner via the Gyan Continuous Knowledge Portal (Fig. 3) or optionally integrated into the Institution’s LMS system via the Gyan Course Workbench.
At a major global educational institution, Gyan is being used to rapidly decompose massive amounts of existing content to granular levels of learning units and supplemented with external content in order to enable the creation of new learning modules on demand. The institution can mix and match its granular learning units to meet new learning needs.
The content can be personalized to individual learner as needed. Personalization can be based on the individual learner’s learning preferences.
Fig. 5-9 show screen shots from the machine that an institution’s designer can follow to assemble new courses/learning units in a matter of minutes/hours. The Gyan engine automates the discovery of relevant content from existing material which may be non-obvious. For e.g., a global higher ed institution wanted to build a new course on ‘soft skills’. It had relevant material buried in existing course content which was going to be nearly impossible to retrieve through contemporary search technologies. Since the Gyan engine determines relevance based on a complete understanding of the documents, it could find content on topics related to soft skills but expressed differently.
In addition, Gyan can look outward to other sources like the public internet to find additional relevant content. The machine also has substantial intelligence to build the learning outline, create assessments based on a desired scope, and integrate the final course or learning content with popular learning management solutions (LMS). Relevant screen shots from the course assembly machine are reproduced in Figs. 5-9
Fig. 5
Gyan Learning Content Creation Machine – Build New Course

Fig. 6
Gyan Learning Content Creation Machine – Build Content & Outline
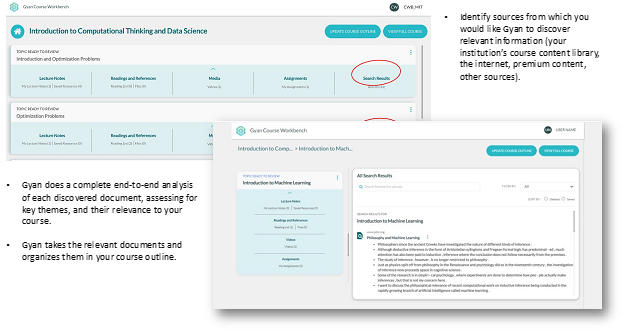
Fig. 7
Gyan Learning Content Creation Machine – Lesson Plan, Lecture Notes
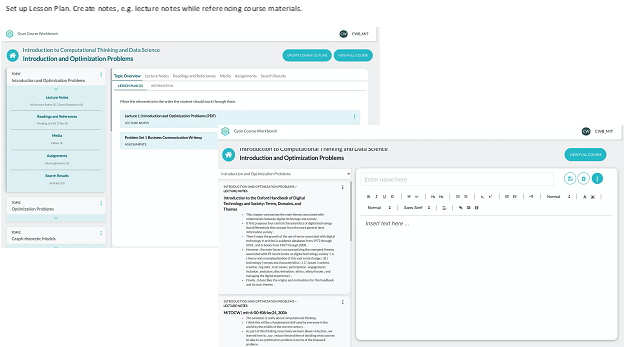
Fig. 8
Gyan Learning Content Creation Machine – Build Assessments
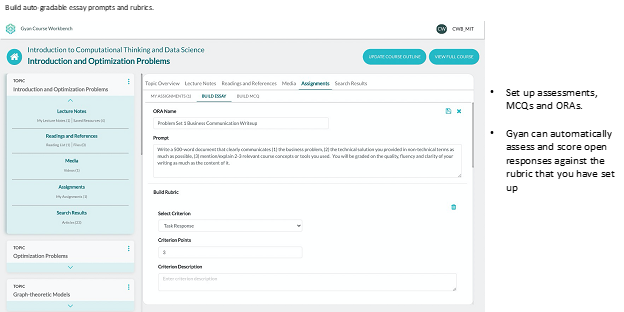
Fig. 9
Gyan Learning Content Creation Machine – Review and Publish
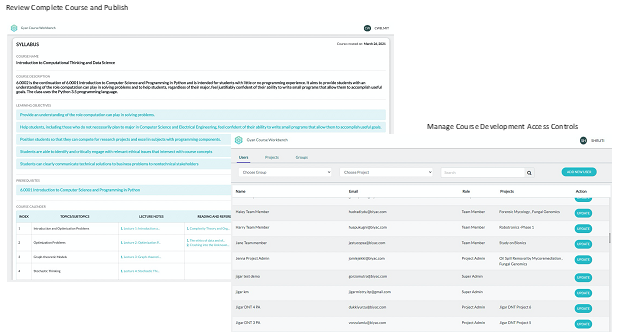
5.0 Scalable Open Text Response Assessment
Human grading of essays and open text responses [ORA] is time consuming and subject to inconsistencies and biases. While there is a significant body of research on automated grading of essays [AES], they have been criticized for lack of context awareness, the need for large volume of training data, data driven biases and their black box nature. Further, in online courses like MOOCs, the common practice is to use peer grading. Peer grading has serious drawbacks as a grading mechanism not the least of which is a natural agency for grade inflation. Gyan addresses these challenges effectively. Gyan can evaluate the essay or ORA in its context, gather intelligence from a sparse data set of labeled essays, be transparent in its reasoning or logic and be tractable so it can be improved in an understandable manner. Besides, Gyan can be configured rapidly to reflect course-specific requirements.
A prominent, globally respected higher educational institution currently uses peer grading in its online courses for open text response assessment. Gyan was tested on a sample question from an engineering course. We selected an assignment from a course that was already graded. For the chosen assignment, the peer graders had given each other perfect scores.
Our team gathered all of the relevant materials for this assignment – the prompt, the rubric, the weights, and supplemental reading materials that students used to answer the assignment. We also collected the assignments that the students submitted. The assignment had 5 questions in total, each question could be scored from 0 – 3 (with three being the highest score). The maximum total score a student could receive was 15 points.
Gyan was configured with the rubric the professor had specified. In this case, the professor only wanted the writing quality and completeness/relevance graded. No weight was given to grammar. After Gyan was configured, all of the submitted assignments were assessed through it. In total, we assessed the assignments of 10 students.
We then requested 3 TAs to grade the same essays manually with the intent of obtaining and comparing against a human baseline.
Fig. 10
Gyan Essay Grading Example
Student | Gyan Scores | Peer Graders Scores | Teaching Assistant Scores (Range) |
1 | 11 | 15 | 8 -11 |
2 | 15 | 15 | 13 - 15 |
3 | 15 | 15 | 13 – 14 (TA #3 did not submit a score) |
4 | 12 | 15 | 11 - 15 |
5 | 13 | 15 | 10 - 14 |
6 | 14 | 15 | 13 - 15 |
7 | 15 | 15 | 10 - 14 |
8 | 12 | 15 | 12 - 15 |
9 | 13 | 15 | 11 - 13 |
10 | 14 | 15 | 13 - 15 |
Fig. 10 presents the results of the pilot. As we can see, the peer grades were perfect scores for all 10 students. The TAs had a wide dispersion for the same essay. For each of the Gyan assessments, a detailed reasoning report was provided to the professor/institution explaining how Gyan arrived at the final score/grade. In all the cases, the professor and TAs agreed with Gyan’s assessment.
6.0 Personalized Learning Pathways
There is a growing willingness among employers to hire people who have the necessary skills for the jobs disregarding the traditional 4-year college degree. Leading employers are placing a greater emphasis on skills, rethinking how meaningful traditional credentials are meaningful like 4-year college degrees and working with educational institutions to create learning programs to develop the talent and workforce they need.
GyanAI has introduced an intelligent machine to enable the automated creation of personalized learning pathways for individuals. These can be career linked or used by the individual on their own. This is already being used by a global higher educational institution and a startup focused on career guidance for unemployed adults.
Fig. 11
GyanAI Personalized Learning Pathway Machine

The machine shown in Fig. 11 starts with the individual uploading their resume or profile. It uses natural language processing to extract skills from the resume and attempts to grade the level of the skill based on a combination of education and experience. The machine relies on natural language processing to extract and normalize skills from the user’s resume. The user has the ability to modify and/or complete the machine’s extraction and interpretation. The machine is able to process various sections in the resume – education, experience, purpose, skills explicitly mentioned. Along with Skills, the machine also determines as much as possible from the information in the resume a proficiency level for each of the skills. The machine is integrated with any skills taxonomy like ONET, EMSI Burning Glass or a proprietary taxonomy specific to the employer.
GyanAI can process any resume. Fig. 12 is a real resume processed by the machine and partial output from the machine for illustration purposes.
Fig. 12
A Resume Example

The machine also identifies the skill gap between the person’s skills as indicated in the resume and a desired occupation. The skills extracted from the resume are normalized by the machine to a chosen skills taxonomy like ONET. The normalized skills are then compared to a desired occupation to identify the person’s skill gap for that occupation.
7.0 Getting Your Digital Content Found!
Improving discoverability of content in an institutional library typically requires the manual creation of tags and / or an elaborate manually created content organization (e.g. a hierarchical structure). Staying ahead of this tagging process as new content arrives is equally challenging. Automatically generating high quality tags would not only make this process much more efficient, it would also make tagging content at a much larger scale feasible.
With its computational linguistics based language model, Gyan is capable of 0-shot/few shot learning. We used Gyan in a pilot project which required Gyan to generate tags that best describe a document to maximize discoverability in search by customers/prospects.
Fig. 13
Gyan Topic Identification Example

As shown in Fig. 13, in a sample of 7 articles, Gyan found 80% match with its tags with no training data which was orders of magnitude better than contemporary LMs. A leading LM with no task specific training found only 20% of the tags accurately on the same data.
References
Srinivasan, V. (2017) The Intelligent Enterprise in the Era of Big Data, John Wiley & Sons, New York, NY, 2017.
Srinivasan, V. (2021) AI & Learning: A Preferred Future, Computers and Education: Artificial Intelligence, 3 (2022) 100062.
Srinivasan, V. and Jatav, V. (2022) Improving Search Relevance. Working Paper, GyanAI, Inc. 2022.
All rights reserved May 2022